Research note for a new project. The meaning of term Edge Storage may differ from what you’d expect.
Concepts
Defining “Edge”
What it usually mean?
- 边缘存储
- 星际云通
- 边缘计算:分布式存储的另一种可能
- 边缘计算:跨越传统数据中心
- original whitepaper on OpenStack
- Open Glossary of Edge Computing
一般定义与应用场景
边缘计算是为应用开发者和服务提供商在网络的边缘侧提供云服务和 IT 环境服务,目标是在靠近数据输入或用户的地方提供计算、存储和网络带宽。边缘计算着重解决的问题是传统云计算(或中央计算)模式下存在的高延迟、网络不稳定和低带宽的问题。
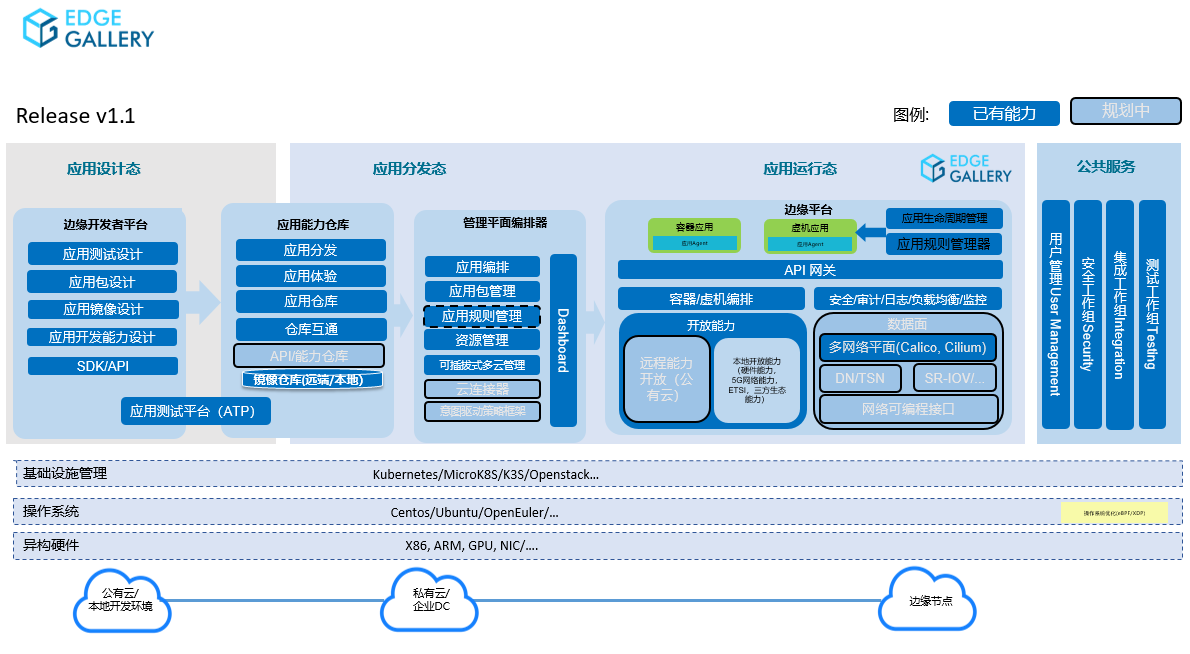 |
|---|
| EdgeGallery v1.1 版本架构图 |
边缘存储(Edge Storage)就是把数据直接存储在数据采集点,而不需要把采集的数据通过网络(即时)传输到存储的数据中心服务器(或云存储)的数据存储方式。例如:
- 公共监控摄像:在摄像头本地保存数据,即时处理(Axis)
- 家庭数据中心:用户希望数据存储在自己家中,而不是存储与安全防护的公司,希望公司不接触数据,兼顾隐私与安全
- 车联网采集数据:往往可以在端进行先期处理,把整理后的少量数据传给数据中心
 |
|---|
| 星际云通总体架构 |
边缘计算适用于与物联网设备紧密相关、数据传输延迟敏感、数据交互次数多、数据传输量大的物联网应用;而云存储则适用于延迟敏感度稍低的互联网应用。
一般“边缘计算”指“计算”下沉至“端”场景
边缘计算的好处
- 网络带宽的有效利用
- 降低延迟
- 消除网络依赖
- 部署将更加容易
- 容错性更强
- 安全与隐私兼顾
- 与边缘计算结合
- 数据实时性、时效性
边缘计算环境的特点
- 多个站点之间的潜在高延迟
- 网络不可达、慢速带宽
- 伴随一般数据中心中心化资源池所不能应对的其他交付服务和应用功能
边缘计算的能力
- 提供一个跨多种基础设施的一致性操作范式
- 能够支持大规模分布式环境
- 能够为全球分布的客户交付网络服务
- 能够满足应用集成、编排和服务交付的需求
- 能够满足硬件资源的限制和成本的限制
- 能够运行在局限及不稳定的网络之上
- 能够满足应用对超低延迟的需求
- 能够实现区域隔离,保护本地数据的隐私
边缘计算的部署/管理挑战
- 需要标准化的和统一的基础环境。每个区域具有类似架构、已知数量
- 提供自动化管理;在处理部署、更替任何可复原性故障时提供简洁直接的(simple and straightforward)处理方法
- 当硬件出现故障时,提供简洁高效的(simple, cost-effective)应对计划
- 本地式容错设计也不容忽视,尤其是面对远程或不可达环境,零接触式的管理模式
- 维护操作必须简洁。未经过培训的工人能够进行人工修复和替换,而熟练的远程管理员可以进行重装或软件维护
- 物理设计可能需要整体反思。大多数的边缘计算环境并不理想,有限的能源、灰尘、湿度及震动都应该被考虑在内
基础设施也必须支持容器化部署。容器运行环境有其本带的问题:
- 若使用内核驱动,则需要其支持命名空间
- 多数硬件接口,包括 iSCSI,暂无支持方案
- IOMMU / SR-IOV
- 天生对系统服务不友好
/var目录管理困难- 内核空间相互隔离
- 无第一方持久化存储支持
- 映射挂载目录 / 设备文件 / 文件镜像

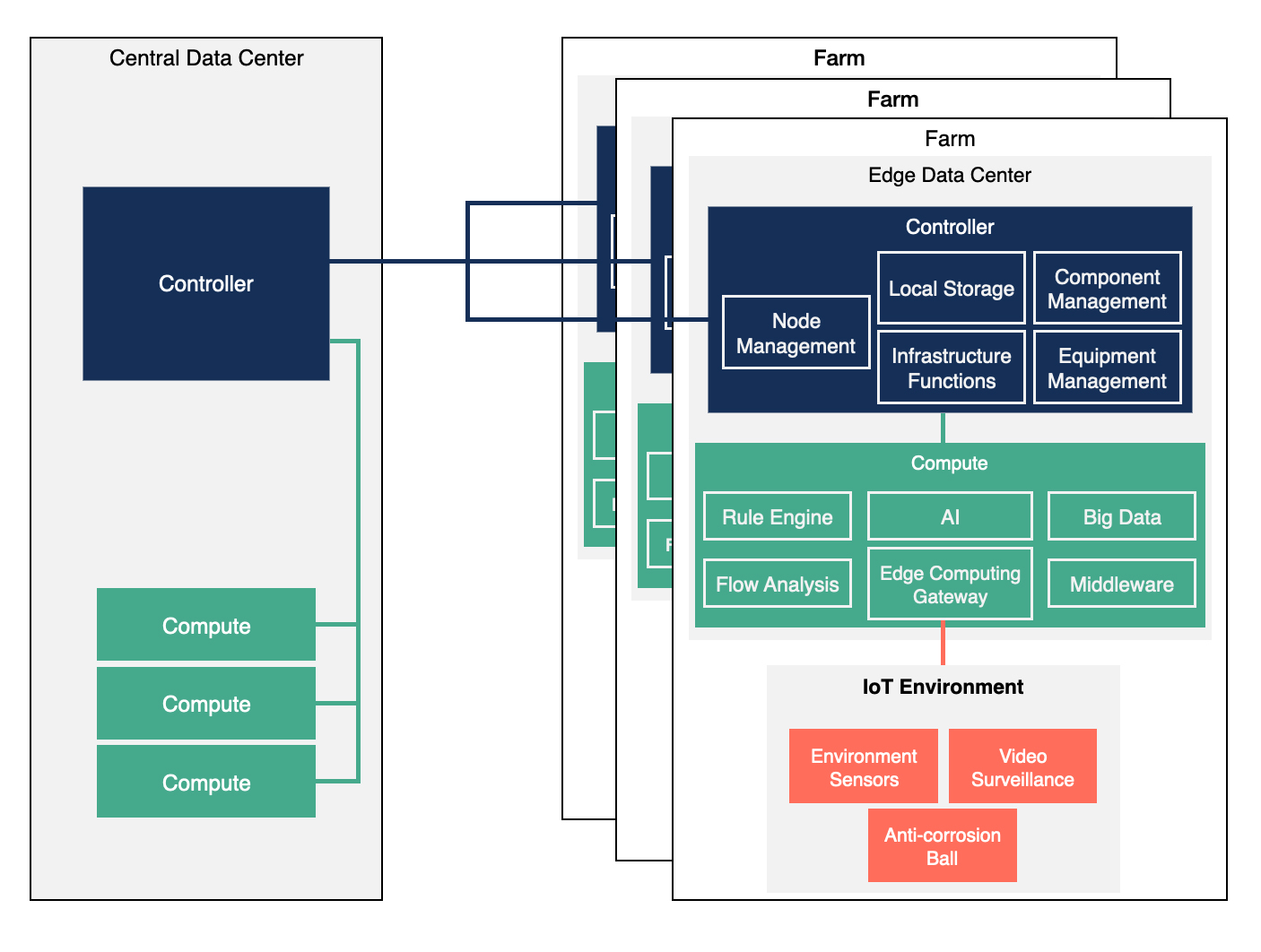 |
|---|
| A detailed view of the edge data center with an automated system used to operate a shrimp farm |
边缘计算模型
边缘计算模型一般分为 控制平面 与 数据平面 两个解耦的部分讨论
中心式控制平面 Centralized Control Plane
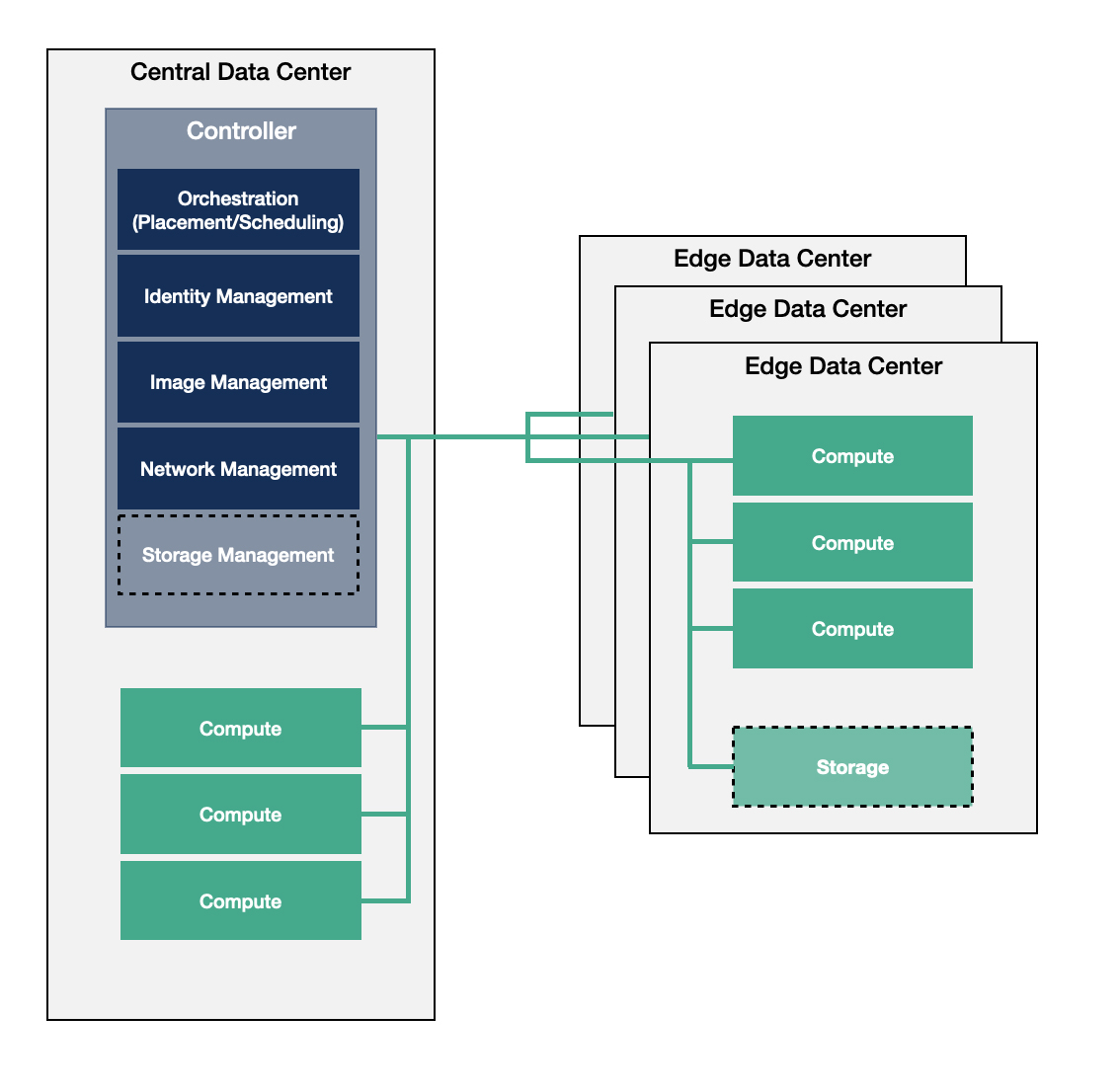
Edge infrastructures is built as traditional single data center environment which is geographically distributed with WAN connections between the controller and compute nodes.
Compute services incoporate running bare metal, containerized and virtualized workloads alike.
While the management and orchestration services are centralized, this architecture is less resilient to failures from network connection loss. The edge data center does not have full automony.
In summary, this architecture model does not fulfill every use case, but it provides an evolution path to already existing architectures. Plus, it also suits the needs of scenarios where autonomous behavior is not a requirement.
分布式控制平面 Distributed Control Plane
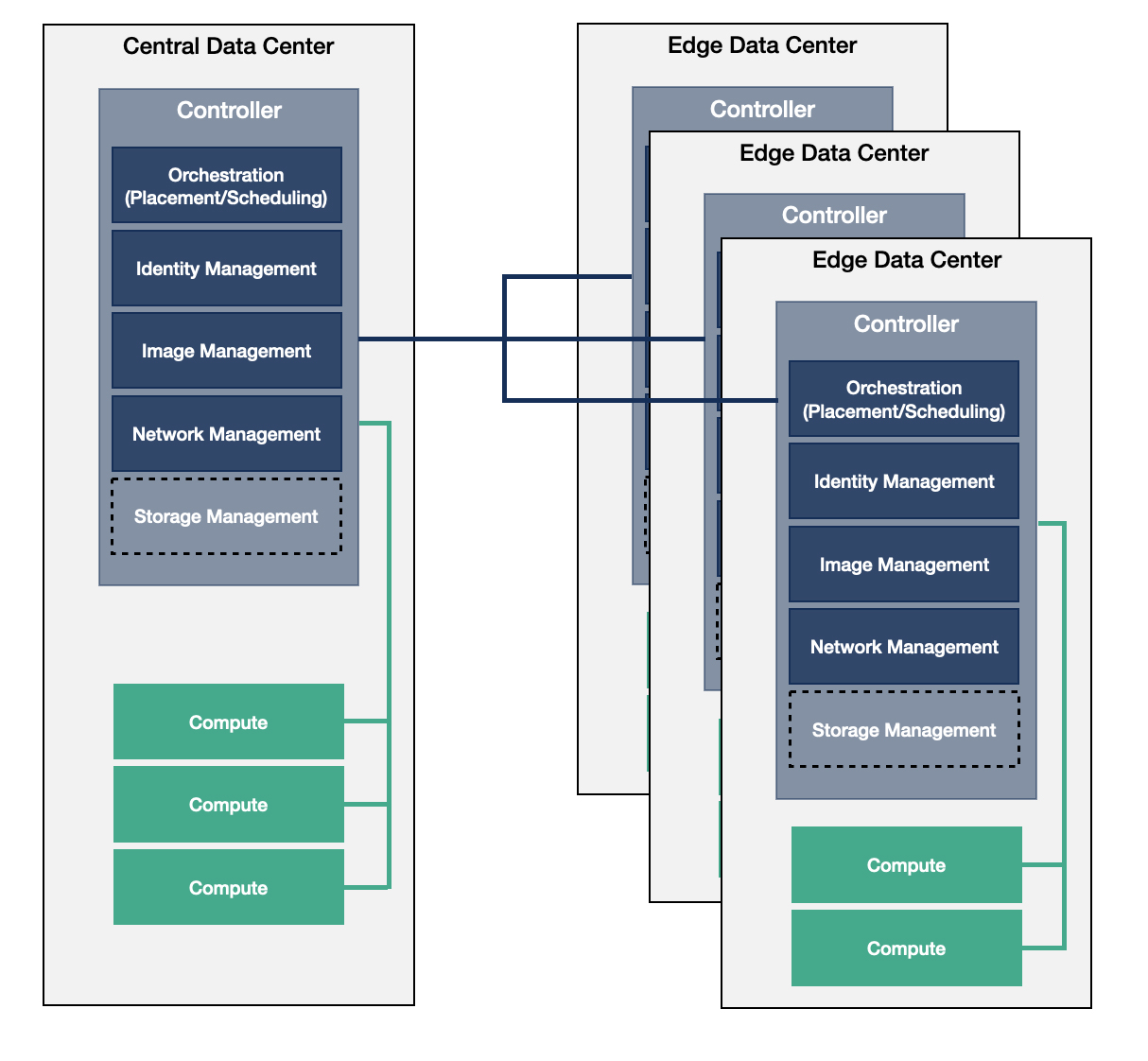
The majority of the control services redie on the large/medium edge data centers. This provides an orchestrational overhead to synchronize between these data centers and manage them individually and as part of a large, connected environment at the same time.
云-边半对等模型,根据服务质量需要来相互“卸载”计算任务
 |
|---|
| StarlingX Distributed Cloud |
基于边缘存储的点对点网络
网络加速,利用边缘存储建立分发网络。由于设备非常分散,分发加速的效果将远远好于当前站点有限的 CDN 网络。
当边缘存储进入实用阶段,去中心化的应用也更容易建立。由于基于边缘存储的点对点网络的建立,使得应用或服务商之间的数据共享变得更加容易和便捷:服务商或应用提供商完全可以不拥有数据,数据本身属于数据的生产者,数据的拥有者可以选择把数据分享给不同的应用或服务。
商业模式:用户信息存储不再与某一个服务提供商绑定
In our context
Intuition
网络分块(Partition)更加明显的数据中心。
分块内的网络与分块之间的网络有明显的性能异构性,甚至可能在接入方式上也异构(但该差异通过 NFV 技术消除,似乎与电信行业密切相关)。
在项目的上下文中,边缘存储 更多是指 边缘数据中心 上的分布式持久化存储。
边缘数据中心
边缘数据中心在靠近用户的网络边缘提供基础设施资源,支持边缘计算对本地化、实时性的数据进行分析、处理、执行以及反馈,从而对云计算能力进行补充。借助边缘计算,数据可以在边缘数据中心进行处理,从而节省到传统集中式数据中心的通信等待时间。
分类思路
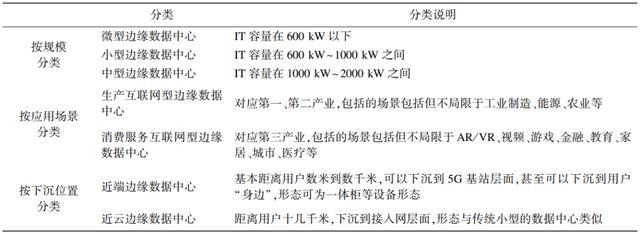
- 电力规划与接入
- 应用场景
- 下沉位置:近端 vs. 近云
规划与设计
靠近用户、物理分散、逻辑统一
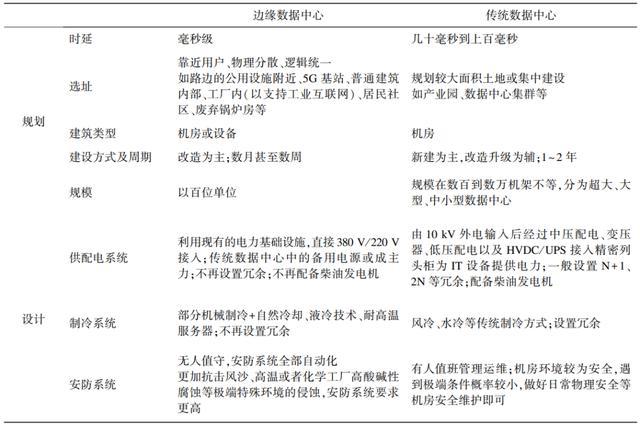
发展方向
- 模块化
- 预制产品化
- 游牧数据中心(Nomadic Data Center)
Nawab F, Agrawal D, El Abbadi A. Nomadic datacenter sat the network edge: Data management challenges for the cloud with mobile infrastructure[C]. EDBT, 2018:497-500.
- 游牧数据中心(Nomadic Data Center)
-
标准化
新华三边缘数据中心机房采用微模块标准化建设模式,提供标准接口、部件、子系统、整体架构全方位标准化、模块化定义数据中心,实现客户按需定制,非常适合多站融合边缘计算场景的云基础设施快速部署。
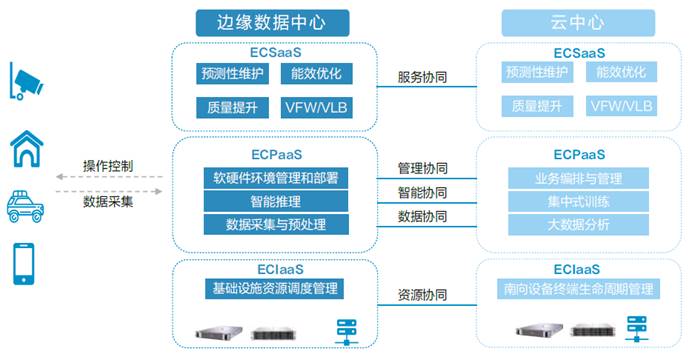
新华三云边协同处理流程
Network Functions Virutalization (NFV)
- Network Function Virtualization – The Opportunity for OpenStack and Open Source
- TelcoWorkingGroup - OpenStack
- What is Network Functions Virtualization?
主要与电信(Telco)行业相关
Background
The networking industry is changing:
-
Disaggregation of control plane and data plane
Taking the current architecture of proprietary, expensive, complex, difficult-to-manage forwarding devices (e.g. routers) and SDN aims to “put an API on it”, forwarding devices become devices controlled by open standards.
-
A shift in the telco data-center world which embraces lessons from elastic infrastructure cloud
-
Disaggregation of hardware and software
The software part can be open-source implementations of optimized packet-forwarding capabilities which used to be implemented in expensive and proprietary hardware appliances (or “middleboxes”).
The main consumers of NFV are Service providers who are looking to accelerate the deployment of new network services.
NFV is a complementary initiative to SDN, and SDN makes using NFV much easier and better.
电信提供商希望通过引入云计算中的、基于虚拟化技术的服务管理模式来在基础设施共用的环境下降低运营成本、加速功能迭代
通过 NFV 技术使用虚拟化消除接入方式的不同
NFV Architecture
 |
|---|
| The Architectural Framework proposed by ETSI NFV ISG. The grey lines show the main reference points, where green lines and blue lines show the execution and other reference points, respectively. |
Main blocks of NFV framework are:
- Infrastructure consisting of hardware resources and corresponding virtualization
- Management and Orchestration (MANO), consisting of orchestrator, virtualized network functions manager (VNFM) and Virtualized Infrastructure Manager (VIM)
- Virtualized network function and corresponding element management systems (EMS)
- Operating Support System and Business Support Systems (OSS/BSS)
A Virtualized Network Function (VNF) is a Network Function capable of running on an NFV Infrastructure (NFVI) and being orchestrated by a NFV Orchestrator (NFVO) and VNF Manager.
The NFVI is the totality of the hardware and software components which build up the environment in which VNFs are deployed.
NFV decouples software implementations of Network Functions from the compute, storage, and networking resources through a virtualized layer.
The combination of NFVO, VIM and VNFM is typically referred as MANO. NVFO is responsible for initialization and setup of new network services, network service lifecycle management, global resource management, validation and authorization of requests for NFVI, as well as policy management for network service instances.
VNFMs are responsible for lifecycle management of VNF instances and the overall coordination between NFVI and EMSs.
VIM, such as OpenStack, is responsible for controlling, managing and monitoring NFVI compute, storage and network resources.
 |
|---|
| OPNFV Release Architecture |
NFV 的具体实现形式尚未知
其他材料
网络拓扑发现 Network Topology Discovery
- Current Trends of Topology Discovery in OpenFlow-based Software Defined Network
- Discovering the Network Topology: An Efficient Approach for SDN
通过 Dijkstra-like 算法找到由网络延迟定义的最短生成路径
- Discovering the Network Topology: An Efficient Approach for SDN
- Efficient topology discovery in software defined networks
在 SDN 中(基于 OpenFlow 交换机抽象)通常通过二层协议 LLDP(Link Layer Discovery Protocal)实现,SDN 交换机默认支持 LLDP,但网络拓扑发现的计算仍由 SDN 控制器完成,且该实现并未标准化(但通常认为 NOX 的实现,OFDP - OpenFlow Discovery Protocal,为标准实现)。
NOTE
SDN 中不存在“路由器”概念,路由功能(即报文受控转发)由 SDN 交换机完成。
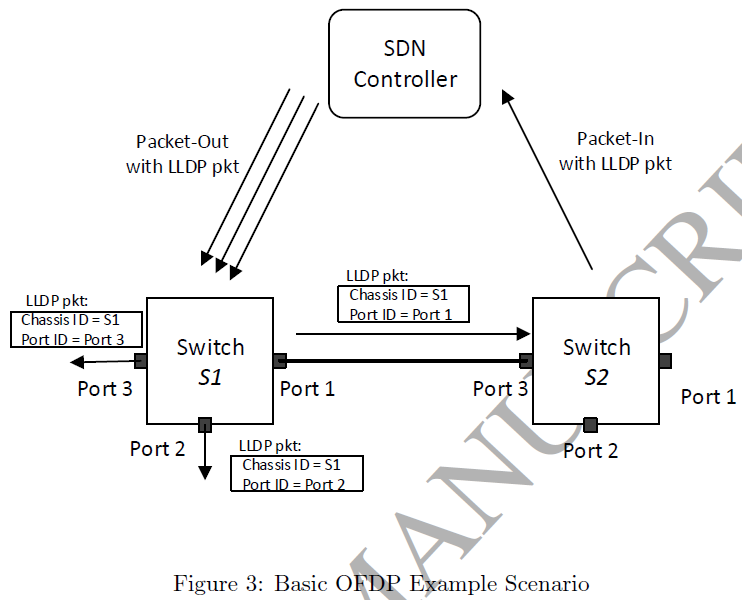 |
|---|
| OFDP 工作流程:控制器通过 Packet-In 报文发现连接 (S1.P1, S2.P3) |
若网络中的传统交换机不支持 LLDP,其二层报文会被直接丢弃。可以利用广播机制来使报文“穿过”传统交换机(如 BDDP,Broadcast Domain Discovery Protocal,非标准协议)。
暂无发现传统交换机的方法,因为传统交换机在逻辑上是透明的。
Implementation and Deployment
Ceph at the Edge
Use Mars 400 Ceph Storage in Edge Datacenter
- 数据服务器小型化、可热插拔
- 主要针对私有云场景
After a series of local data processing, the result and original datasets are stored in the edge data center. The application only uploads precise result back to the central datacenter.
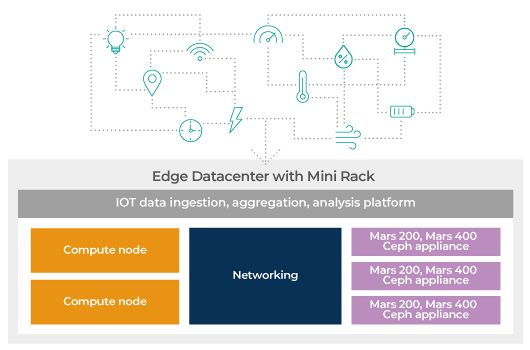
Key reason this IoT application leads to use of Ceph:
- Scalability with high availability
- A storage system with unified storage protocal
- A software-defined storage sytem can start from a mini-cluster
Every ARM server node provides dedicated CPU, memory, storage and network interface resources to its supported object storage device (OSD). As a result, OSD performance is far more balanced than traditional single-server node designs supporting many OSDs. Also, by limiting the failure domain to a single disk, the Mars exhibits faster recovery from microserver failures.
OpenStack and Ceph for Distributed Hyperconverged Edge Deployments
OpenStack 边缘计算/超融合架构路线书
与 Canonical 合作,基于 LXD 容器;官方 Docker 容器支持情况位置
… The resultant architecture will support NFV (which is backbone technology for 5G), emerging use cases with fewer control planes and distribute VNFs (Virtual Network Functions or network services) within all regional and edge nodes involved in network.
 |
|---|
| Proposed solution referred Akraino Edge Stack (Software stack for Edge, Linux Foundation Open Source Project) |
-
Ceph

Ceph for the proposed architecture 
Distributed Compute Nodes with Ceph 
Final Architecture showing OpenStack projects + Ceph Cluster in HCI Way
What is MEC? The telco Edge. - Canonical
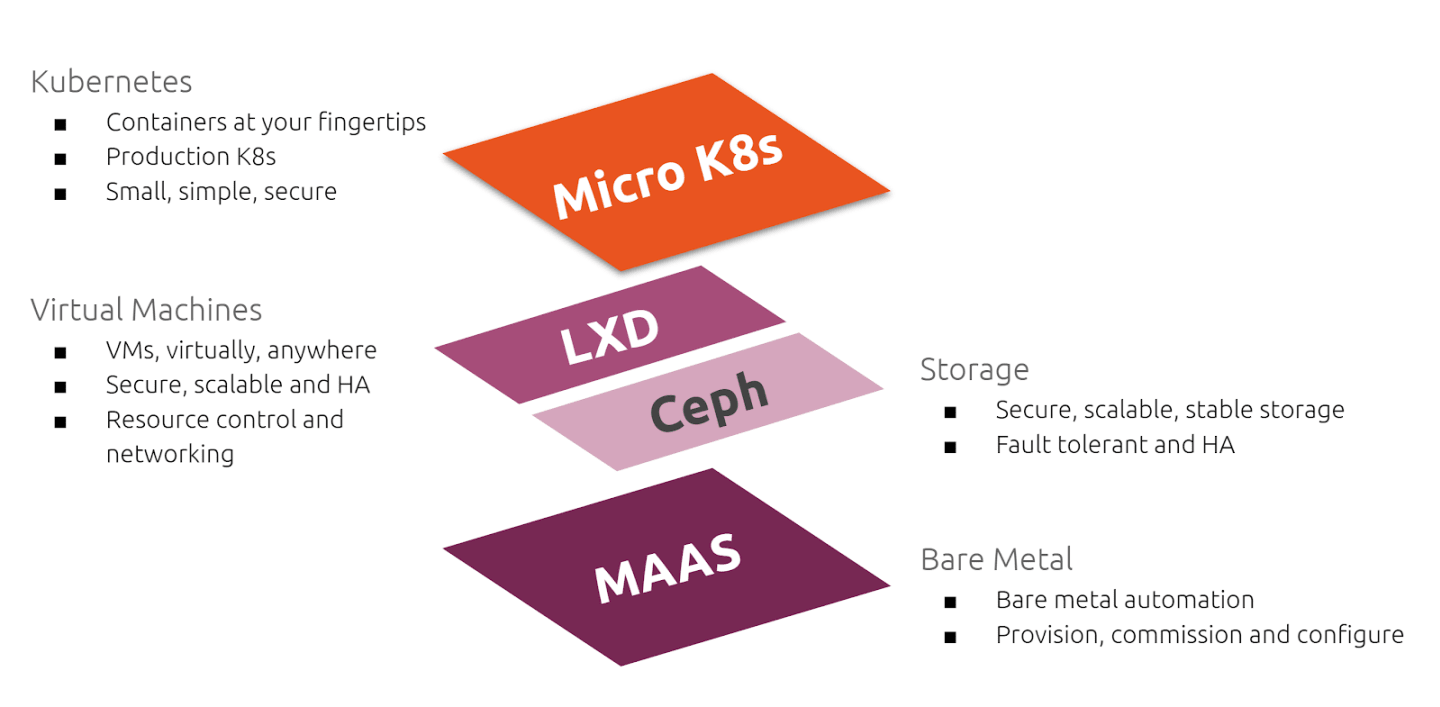 |
|---|
| Typical edge site design |
- MaaS to manage bare metal hardware
- LXD clustering to provide an abstract layer of virtualization
- Ceph for distributed storage
- MicroK8s to provide a Kubernetes cluster
TODO:
Ceph with Partitioned Network
TODO:
Idea
- CRUSH & 带权图
- 延迟定义的带权图
- 模糊指定副本放置位置
- 确保副本在地理上邻近
- 确保降级副本离主副本不远
- 最快主副本恢复流量调度
- 带权图如何与 CRUSH Map 一起在集群中同步?
- 必要性:CRUSH 为启发式数据放置算法,必须保证算法的输入在所有节点上一致!
- 元数据同步开销可能过大,从树变成图
- 使用 Ceph 的增量 gossip?
- …
Oberservation
-
当 pool 跨多个分区时,分区间延迟对读写性能影响大小依次为 随机读 » 顺序读 > 随机写。
-
Inter-partition Lat. Write IOPS / Lat. Seq IOPS / Lat. Rand IOPS / Lat. +0ms 33 / 0.47 377 / 0.04 7305 / 0.002 +50ms 24 / 0.65 118 / 0.13 254 / 0.06 - 延迟加在网络界面上,即 RT 延迟为所加延迟的两倍
- CRUSH 规则选择 host 作为叶子节点,即三个副本分布在三个节点(也即网络分区)上
rados -p test -b 4K [-O 4M] bench 180 write [-t 16] --no-cleanup
-
Approach
Target data placement
对于一个 3-副本(及以上)的存储池,我们希望其中
- 前两个副本在离计算较近的节点,降低主要副本发生故障时的恢复时间
- 第三个(及以上)副本在离计算较远的节点,保障发生关联故障时的数据安全
Vanilla CRUSH approach
Intuition
-1 0.04500 root default
-3 0.01500 host kart-1
0 hdd 0.00499 osd.0 up 1.00000 1.00000
1 hdd 0.00499 osd.1 up 1.00000 1.00000
2 hdd 0.00499 osd.2 up 1.00000 1.00000
-5 0.01500 host kart-2
3 hdd 0.00499 osd.3 up 1.00000 1.00000
4 hdd 0.00499 osd.4 up 1.00000 1.00000
5 hdd 0.00499 osd.5 up 1.00000 1.00000
-7 0.01500 host kart-3
6 hdd 0.00499 osd.6 up 1.00000 1.00000
7 hdd 0.00499 osd.7 up 1.00000 1.00000
8 hdd 0.00499 osd.8 up 1.00000 1.00000
对于这样集群结构,我们可以在 CRUSH Map 中人为配置与现实情况相符的分区。
-9 0.01500 region only-kart-1
-3 0.01500 host kart-1
0 hdd 0.00499 osd.0 up 1.00000 1.00000
1 hdd 0.00499 osd.1 up 1.00000 1.00000
2 hdd 0.00499 osd.2 up 1.00000 1.00000
-11 0.03000 region except-kart-1
-5 0.01500 host kart-2
3 hdd 0.00499 osd.3 up 1.00000 1.00000
4 hdd 0.00499 osd.4 up 1.00000 1.00000
5 hdd 0.00499 osd.5 up 1.00000 1.00000
-7 0.01500 host kart-3
6 hdd 0.00499 osd.6 up 1.00000 1.00000
7 hdd 0.00499 osd.7 up 1.00000 1.00000
8 hdd 0.00499 osd.8 up 1.00000 1.00000
然后在人为构造的辅助分区上构建规则。
rule kart-1_centric {
id 1
type replicated
min_size 3
max_size 10
step take only-kart-1
step chooseleaf firstn 2 type osd
step emit
step take except-kart-1
step chooseleaf firstn 0 type osd
step emit
}
这里由于测试环境硬件条件限制,故障域为
host,故叶子节点只能为osd。
- 对于 n 个分区会产生 O(n) 个辅助分区
- 添加新故障域的 Bucket 时需要更新所有现有的辅助分区,且为了负载均衡会导致必要数据迁移
可以通过脚本生成 CRUSH Map
- 获取当前 CRUSH Map
-
JSON:
ceph osd crush dumpinterface CRUSHMap { devices: { id: number, name: string, class: "hdd" | "ssd" | "nvme" }[], types: { type_id: number, name: string }[], buckets: { id: number, name: string, type_id: number, type_name: string, weight: /*16.16 fixed-point*/number, alg: "uniform" | "list" | "tree" | "straw" | "straw2", hash: "rjenkins1", items: { id: number, weight: /*16.16 fixed-point*/number, pos: number }[] }[], rules: { rule_id: number, rule_name: string, ruleset: number, type: number, min_size: number, max_size: number, steps: ( { op: "take", item: number, item_name: string } | { op: "choose_firstn" | "choose_indep" | "chooseleaf_firstn" | "chooseleaf_indep", num: number, type: string } | { op: "emit" } )[] }[], tunables: any, choose_args: any } -
二进制:
ceph osd getcrushmap -o <bin>
-
- 反编译二进制 CRUSH Map:
crushtool -d <bin> -o <txt> - 编译二进制 CRUSH Map:
crushtool -c <txt> -o <bin> - 更新 CRUSH Map:
ceph osd setcrushmap -i <bin>
Implementation
脚本生成的 CRUSH Map
受 CRUSH Rule 语义限制,这里采用的实现方式为对每一个故障域都定义一个独立的 CRUSH Rule。
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
# 设置为较高数值可以让副本选择更稳定,在更变 pool 的 CRUSH Rule 时数据迁移最少
tunable chooseleaf_vary_r 10
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
device 9 osd.9 class hdd
device 10 osd.10 class hdd
device 11 osd.11 class hdd
device 12 osd.12 class hdd
device 13 osd.13 class hdd
device 14 osd.14 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host kart-1 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.015
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.005
item osd.1 weight 0.005
item osd.2 weight 0.005
}
host kart-2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.015
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.005
item osd.4 weight 0.005
item osd.5 weight 0.005
}
host kart-5 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.015
alg straw2
hash 0 # rjenkins1
item osd.12 weight 0.005
item osd.9 weight 0.005
item osd.6 weight 0.005
}
host kart-4 {
id -9 # do not change unnecessarily
id -10 class hdd # do not change unnecessarily
# weight 0.015
alg straw2
hash 0 # rjenkins1
item osd.10 weight 0.005
item osd.14 weight 0.005
item osd.7 weight 0.005
}
host kart-3 {
id -11 # do not change unnecessarily
id -12 class hdd # do not change unnecessarily
# weight 0.015
alg straw2
hash 0 # rjenkins1
item osd.11 weight 0.005
item osd.13 weight 0.005
item osd.8 weight 0.005
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.073
alg straw2
hash 0 # rjenkins1
item kart-1 weight 0.015
item kart-2 weight 0.015
item kart-5 weight 0.015
item kart-4 weight 0.015
item kart-3 weight 0.015
}
root CephEdge-except_kart-1 {
id -13 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
# weight 0.059
alg straw2
hash 0 # rjenkins1
item kart-2 weight 0.015
item kart-5 weight 0.015
item kart-4 weight 0.015
item kart-3 weight 0.015
}
root CephEdge-except_kart-2 {
id -15 # do not change unnecessarily
id -16 class hdd # do not change unnecessarily
# weight 0.059
alg straw2
hash 0 # rjenkins1
item kart-1 weight 0.015
item kart-5 weight 0.015
item kart-4 weight 0.015
item kart-3 weight 0.015
}
root CephEdge-except_kart-5 {
id -17 # do not change unnecessarily
id -18 class hdd # do not change unnecessarily
# weight 0.059
alg straw2
hash 0 # rjenkins1
item kart-1 weight 0.015
item kart-2 weight 0.015
item kart-4 weight 0.015
item kart-3 weight 0.015
}
root CephEdge-except_kart-4 {
id -19 # do not change unnecessarily
id -20 class hdd # do not change unnecessarily
# weight 0.059
alg straw2
hash 0 # rjenkins1
item kart-1 weight 0.015
item kart-2 weight 0.015
item kart-5 weight 0.015
item kart-3 weight 0.015
}
root CephEdge-except_kart-3 {
id -21 # do not change unnecessarily
id -22 class hdd # do not change unnecessarily
# weight 0.059
alg straw2
hash 0 # rjenkins1
item kart-1 weight 0.015
item kart-2 weight 0.015
item kart-5 weight 0.015
item kart-4 weight 0.015
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule CephEdge-kart-1_centric {
id 1
type replicated
min_size 3
max_size 10
step take kart-1
step chooseleaf firstn 2 type osd
step emit
step take CephEdge-except_kart-1
step chooseleaf firstn 0 type host
step emit
}
rule CephEdge-kart-2_centric {
id 2
type replicated
min_size 3
max_size 10
step take kart-2
step chooseleaf firstn 2 type osd
step emit
step take CephEdge-except_kart-2
step chooseleaf firstn 0 type host
step emit
}
rule CephEdge-kart-5_centric {
id 3
type replicated
min_size 3
max_size 10
step take kart-5
step chooseleaf firstn 2 type osd
step emit
step take CephEdge-except_kart-5
step chooseleaf firstn 0 type host
step emit
}
rule CephEdge-kart-4_centric {
id 4
type replicated
min_size 3
max_size 10
step take kart-4
step chooseleaf firstn 2 type osd
step emit
step take CephEdge-except_kart-4
step chooseleaf firstn 0 type host
step emit
}
rule CephEdge-kart-3_centric {
id 5
type replicated
min_size 3
max_size 10
step take kart-3 # 首先从中心故障域选择主要副本
step chooseleaf firstn 2 type osd
step emit
step take CephEdge-except_kart-3 # 之后在其他故障域中选择剩余副本
step chooseleaf firstn 0 type host
step emit
}
# end crush map
实际生成的数据布局如下:
root@kart-1:/# ceph osd tree-from default
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.07500 root default
-3 0.01500 host kart-1
0 hdd 0.00499 osd.0 up 1.00000 1.00000
1 hdd 0.00499 osd.1 up 1.00000 1.00000
2 hdd 0.00499 osd.2 up 1.00000 1.00000
-5 0.01500 host kart-2
3 hdd 0.00499 osd.3 up 1.00000 1.00000
4 hdd 0.00499 osd.4 up 1.00000 1.00000
5 hdd 0.00499 osd.5 up 1.00000 1.00000
-11 0.01500 host kart-3
8 hdd 0.00499 osd.8 up 1.00000 1.00000
11 hdd 0.00499 osd.11 up 1.00000 1.00000
13 hdd 0.00499 osd.13 up 1.00000 1.00000
-9 0.01500 host kart-4
7 hdd 0.00499 osd.7 up 1.00000 1.00000
10 hdd 0.00499 osd.10 up 1.00000 1.00000
14 hdd 0.00499 osd.14 up 1.00000 1.00000
-7 0.01500 host kart-5
6 hdd 0.00499 osd.6 up 1.00000 1.00000
9 hdd 0.00499 osd.9 up 1.00000 1.00000
12 hdd 0.00499 osd.12 up 1.00000 1.00000
root@kart-1:/# for r in CephEdge-kart-{1..5}_centric; do ceph osd pool set test crush_rule $r; for o in {0..9}; do ceph osd map test $o; done; done
set pool 2 crush_rule to CephEdge-kart-1_centric
osdmap e118 pool 'test' (2) object '0' -> pg 2.f18a3536 (2.16) -> up ([0,1,5,12,7], p0) acting ([0,1,5,12,7], p0)
osdmap e118 pool 'test' (2) object '1' -> pg 2.437e2a40 (2.0) -> up ([2,1,3,9,7], p2) acting ([2,1,3,9,7], p2)
osdmap e118 pool 'test' (2) object '2' -> pg 2.d963a09f (2.1f) -> up ([0,1,11,4,9], p0) acting ([0,1,11,4,9], p0)
osdmap e118 pool 'test' (2) object '3' -> pg 2.cd1043f3 (2.13) -> up ([0,2,7,13,12], p0) acting ([0,2,7,13,12], p0)
osdmap e118 pool 'test' (2) object '4' -> pg 2.d76e1c1b (2.1b) -> up ([1,0,11,6,5], p1) acting ([1,0,11,6,5], p1)
osdmap e118 pool 'test' (2) object '5' -> pg 2.c7c1094d (2.d) -> up ([1,2,8,10,5], p1) acting ([1,2,8,10,5], p1)
osdmap e118 pool 'test' (2) object '6' -> pg 2.d7f5bf23 (2.3) -> up ([1,2,11,14,5], p1) acting ([1,2,11,14,5], p1)
osdmap e118 pool 'test' (2) object '7' -> pg 2.14d0d63a (2.1a) -> up ([2,0,3,6,10], p2) acting ([2,0,3,6,10], p2)
osdmap e118 pool 'test' (2) object '8' -> pg 2.8f0dc6bd (2.1d) -> up ([0,1,10,6,3], p0) acting ([0,1,10,6,3], p0)
osdmap e118 pool 'test' (2) object '9' -> pg 2.a81d0697 (2.17) -> up ([1,2,5,6,11], p1) acting ([1,2,5,6,11], p1)
set pool 2 crush_rule to CephEdge-kart-2_centric
osdmap e119 pool 'test' (2) object '0' -> pg 2.f18a3536 (2.16) -> up ([5,3,7,12,0], p5) acting ([5,3,7,12,0], p5)
osdmap e120 pool 'test' (2) object '1' -> pg 2.437e2a40 (2.0) -> up ([3,5,8,9,2], p3) acting ([3,5,8,9,2], p3)
osdmap e120 pool 'test' (2) object '2' -> pg 2.d963a09f (2.1f) -> up ([4,3,0,9,11], p4) acting ([4,3,0,9,11], p4)
osdmap e120 pool 'test' (2) object '3' -> pg 2.cd1043f3 (2.13) -> up ([3,4,7,13,0], p3) acting ([3,4,7,13,0], p3)
osdmap e120 pool 'test' (2) object '4' -> pg 2.d76e1c1b (2.1b) -> up ([5,3,11,6,14], p5) acting ([5,3,11,6,14], p5)
osdmap e120 pool 'test' (2) object '5' -> pg 2.c7c1094d (2.d) -> up ([5,3,8,10,1], p5) acting ([5,3,8,10,1], p5)
osdmap e120 pool 'test' (2) object '6' -> pg 2.d7f5bf23 (2.3) -> up ([5,4,11,14,9], p5) acting ([5,4,11,14,9], p5)
osdmap e120 pool 'test' (2) object '7' -> pg 2.14d0d63a (2.1a) -> up ([3,4,11,6,2], p3) acting ([3,4,11,6,2], p3)
osdmap e120 pool 'test' (2) object '8' -> pg 2.8f0dc6bd (2.1d) -> up ([3,5,10,6,8], p3) acting ([3,5,10,6,8], p3)
osdmap e120 pool 'test' (2) object '9' -> pg 2.a81d0697 (2.17) -> up ([5,3,1,6,11], p5) acting ([5,3,1,6,11], p5)
set pool 2 crush_rule to CephEdge-kart-3_centric
osdmap e121 pool 'test' (2) object '0' -> pg 2.f18a3536 (2.16) -> up ([8,11,5,12,7], p8) acting ([8,11,5,12,7], p8)
osdmap e122 pool 'test' (2) object '1' -> pg 2.437e2a40 (2.0) -> up ([8,11,3,9,2], p8) acting ([8,11,3,9,2], p8)
osdmap e122 pool 'test' (2) object '2' -> pg 2.d963a09f (2.1f) -> up ([11,13,0,4,9], p11) acting ([11,13,0,4,9], p11)
osdmap e122 pool 'test' (2) object '3' -> pg 2.cd1043f3 (2.13) -> up ([13,8,7,3,0], p13) acting ([13,8,7,3,0], p13)
osdmap e122 pool 'test' (2) object '4' -> pg 2.d76e1c1b (2.1b) -> up ([11,13,6,5,14], p11) acting ([11,13,6,5,14], p11)
osdmap e122 pool 'test' (2) object '5' -> pg 2.c7c1094d (2.d) -> up ([8,13,12,10,1], p8) acting ([8,13,12,10,1], p8)
osdmap e122 pool 'test' (2) object '6' -> pg 2.d7f5bf23 (2.3) -> up ([11,13,14,5,9], p11) acting ([11,13,14,5,9], p11)
osdmap e122 pool 'test' (2) object '7' -> pg 2.14d0d63a (2.1a) -> up ([11,8,3,6,2], p11) acting ([11,8,3,6,2], p11)
osdmap e122 pool 'test' (2) object '8' -> pg 2.8f0dc6bd (2.1d) -> up ([8,11,10,6,3], p8) acting ([8,11,10,6,3], p8)
osdmap e122 pool 'test' (2) object '9' -> pg 2.a81d0697 (2.17) -> up ([11,8,5,6,1], p11) acting ([11,8,5,6,1], p11)
set pool 2 crush_rule to CephEdge-kart-4_centric
osdmap e123 pool 'test' (2) object '0' -> pg 2.f18a3536 (2.16) -> up ([7,10,5,12,8], p7) acting ([7,10,5,12,8], p7)
osdmap e124 pool 'test' (2) object '1' -> pg 2.437e2a40 (2.0) -> up ([7,10,3,9,2], p7) acting ([7,10,3,9,2], p7)
osdmap e124 pool 'test' (2) object '2' -> pg 2.d963a09f (2.1f) -> up ([10,14,0,4,9], p10) acting ([10,14,0,4,9], p10)
osdmap e124 pool 'test' (2) object '3' -> pg 2.cd1043f3 (2.13) -> up ([7,10,12,13,0], p7) acting ([7,10,12,13,0], p7)
osdmap e124 pool 'test' (2) object '4' -> pg 2.d76e1c1b (2.1b) -> up ([14,7,11,6,5], p14) acting ([14,7,11,6,5], p14)
osdmap e124 pool 'test' (2) object '5' -> pg 2.c7c1094d (2.d) -> up ([10,14,8,5,1], p10) acting ([10,14,8,5,1], p10)
osdmap e124 pool 'test' (2) object '6' -> pg 2.d7f5bf23 (2.3) -> up ([14,10,11,5,9], p14) acting ([14,10,11,5,9], p14)
osdmap e124 pool 'test' (2) object '7' -> pg 2.14d0d63a (2.1a) -> up ([10,14,3,6,2], p10) acting ([10,14,3,6,2], p10)
osdmap e124 pool 'test' (2) object '8' -> pg 2.8f0dc6bd (2.1d) -> up ([10,7,6,3,8], p10) acting ([10,7,6,3,8], p10)
osdmap e124 pool 'test' (2) object '9' -> pg 2.a81d0697 (2.17) -> up ([10,14,5,6,11], p10) acting ([10,14,5,6,11], p10)
set pool 2 crush_rule to CephEdge-kart-5_centric
osdmap e125 pool 'test' (2) object '0' -> pg 2.f18a3536 (2.16) -> up ([12,6,5,7,0], p12) acting ([12,6,5,7,0], p12)
osdmap e125 pool 'test' (2) object '1' -> pg 2.437e2a40 (2.0) -> up ([9,6,3,8,7], p9) acting ([9,6,3,8,7], p9)
osdmap e126 pool 'test' (2) object '2' -> pg 2.d963a09f (2.1f) -> up ([9,6,0,4,11], p9) acting ([9,6,0,4,11], p9)
osdmap e126 pool 'test' (2) object '3' -> pg 2.cd1043f3 (2.13) -> up ([12,6,7,13,0], p12) acting ([12,6,7,13,0], p12)
osdmap e126 pool 'test' (2) object '4' -> pg 2.d76e1c1b (2.1b) -> up ([6,9,11,1,5], p6) acting ([6,9,11,1,5], p6)
osdmap e126 pool 'test' (2) object '5' -> pg 2.c7c1094d (2.d) -> up ([12,9,8,10,1], p12) acting ([12,9,8,10,1], p12)
osdmap e126 pool 'test' (2) object '6' -> pg 2.d7f5bf23 (2.3) -> up ([9,12,11,14,5], p9) acting ([9,12,11,14,5], p9)
osdmap e126 pool 'test' (2) object '7' -> pg 2.14d0d63a (2.1a) -> up ([6,9,3,11,2], p6) acting ([6,9,3,11,2], p6)
osdmap e126 pool 'test' (2) object '8' -> pg 2.8f0dc6bd (2.1d) -> up ([6,9,10,3,8], p6) acting ([6,9,10,3,8], p6)
osdmap e126 pool 'test' (2) object '9' -> pg 2.a81d0697 (2.17) -> up ([6,12,5,11,1], p6) acting ([6,12,5,11,1], p6)
root@kart-1:/#
这样的实现保证了在切换主要工作域时产生的数据迁移是最少的
- 按照数据放置规则要求,主工作域的两个副本必须被替换,因此最多产生 2 个副本的迁移(对象 0 从 kart-1 到 kart-3)
- 若迁移后的次要副本恰好选择了之前的主工作域,则可以少迁移 1 个副本,因此最少产生 1 个副本的迁移(对象 0 从 kart-1 到 kart-2)
| Object ID | Main Failure Domain | Up Set | Up Set (in failure domain) |
|---|---|---|---|
| 0 | kart-1 | [0,1,5,12,7] | [1,1,2,5,4] |
| kart-2 | [5,3,7,12,0] | [2,2,4,5,1] | |
| kart-3 | [8,11,5,12,7] | [3,3,2,5,4] |
Related Readings
- [FAST’19] DistCache: Provable Load Balancing for Large-Scale Storage Systems
with Distributed Cache
- (可编程)交换机辅助
- 对独立哈希的上下两层同时发起读写(power-of-two-choices)
Ceph Cache Tiering 对独立哈希提供原生支持,但暂无同时读写设计
- [ATC’18] STMS: Improving MPTCP Throughput Under Heterogeneous Networks
- 快路与慢路包到达时间差距大,要求有较大重排序缓冲区
- 快路利用率/吞吐量波动大
- 乱序发射、有序到达
- [OSDI’20] Toward a Generic Fault Tolerance Technique for Partial Network Partitioning
-
考察情景:A、B、C 三方中仅 A、B 间通讯受阻,而此时 C 认为集群正常
Ceph OSD peering 问题,进入降级模式。此时的一致性保障、性能指标待考察
- Nifty:通过 Open vSwitch 绕过问题路径
- [OSDI’18] An Analysis of Network-Partitioning Failures in Cloud Systems
- NEtwork pArtitioning Testing framework
-
Misc Readings
- [ATC’20] Fine-Grained Isolation for Scalable, Dynamic, Multi-tenant Edge Clouds
- EdgeOS,为边缘计算设计的操作系统抽象,通过 Feather-Weight Process 降低虚拟化开销
- [ATC’19] FlexGroup Volumes: A Distributed WAFL File System
- NetApp ONTAP 存储操作系统专有
- 按负载信息将不同目录下的文件 / inode 放在不同机器上,且可通过链接在运行时动态地进行负载均衡
- [ATC’18] Fine-grained consistency for geo-replicated systems
- 设计上跟 geo 关系不大
- Partial-Order Restrictions(PoR)一致性:确定一致性不变量条件,当某次写入改变该不变量时,通知更新所有副本
- 与业务逻辑相关
若讨论的上下文为基础设施,则业务逻辑不存在
- [OSDI’18] LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregatoin
- 基于 RDMA 网络的分布式软总线
- 内存/缓存隔离,TLB/MMU 放在远端内存上
- Linux ABI 兼容
- [ATC’20] Disaggregating Persistent Memory and Controlling Them Remotely:
An Exploration of Passive Disaggregated Key-Value Stores
- 数据映射表
- 无锁元数据链表
- [OSDI’20] Storage Systems are Distributed Systems (So Verify Them That Way!)
- 引入编译器检查程序正确性(Dafny)
- [OSDI’20] HiveD: Sharing a GPU Cluster for Deep Learning with Guarantees
- 调度器使用“GPU 数量(quota)”来预留资源,但忽视了所预留 GPU 邻近性(affinity,但 locality 似乎更贴切)的重要性
- 通过类伙伴系统分配“GPU - PCIe 交换设备 - CPU 插槽 - QPI - 机架”结构描述的设备
- 通过 Virtual Private Cloud 抽象供租户使用
- [OSDI’20] Twine: A Unified Cluster Management System for Shared Infrastructure
- 主动控制应用生命周期与性能参数、单一控制平面跨数据中心使用的容器协调器
- K8s 只能控制 5k 大小集群
- 自动系统升级不会重启还在运行其他业务的机器
- 适量调度使用小型机器降低能耗
- 主动控制应用生命周期与性能参数、单一控制平面跨数据中心使用的容器协调器
- [OSDI’18] Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent
Traffic Safely and Efficiently
- 业务流量迁移
- Runbook 自动化运营
- DAG 管理服务依赖
- 周常运维演习
- [FAST’20] BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server
- 充分利用 HDD 的顺序性(sequential & continuous)以及自带的缓冲区
- 降低尾延迟、减少缓存数据交换
- [FAST’20] Transactions and Scalability in Cloud Databases - Can’t We Have Both?
- 类似两段锁/两段事务,但由开发者选择具体检查哪些关键对象
- 基于时序(事务协调器本地时钟)在具体负责关键对象存储的节点上保证 ACID
- 可能导致先发起的事务因持有较慢时钟被拒绝,但这对事务 ACID 正确性并无影响
- 添加了时钟同步服务减少这种“假阳性”冲突