Research notes on the Named Entity Recognition (NER) problem.
Deep text understanding combining Graph Models, Named Entity Recognition and Word2Vec
以前工作
- Maximum Entropy Markov Models for Information Extraction and Segmentation
- Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling
- Neural architectures for named entity recognition
数据
- Wikipedia
- 各实体正交性较强
- 多语言支持
- 知识卡片提供半结构化数据
-
给出同一实体的多个别称、简写
The cornett, cornetto, or zink is an early wind instrument that dates from …
- 指代、简写识别:Stanford CoreNLP
NER 模型
- 训练特定类别实体判别器(从任意文本序列中抽取特定类别的实体)
- GraphAware Neo4j NLP(商用) -> Standford CoreNLP CRF
- 实体可能在多个文章中都出现,取判别为正样本频率高者
- 相似度
- Word2Vec
- 预训练好的词向量:ConceptNet Numberbatch(含中文)
- 在已有词向量库上添加新的实体描述向量
- Word2Vec
==TODO:== 原始 HMM、CRF 太旧了,这里先跳过。
Neural Architectures for Named Entity Recognition
Code
LSTM-CRF Model
听说使用隐层 $\mathbf{h}_t$ 作为判断是否为实体名称的依据很有效??
考虑输入序列
\[\mathbf{X} = (\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_n)\]经过 (Bi-)LSTM 得到输出矩阵 $\mathbf{P} \in \mathbb{R}^{n \times k}$,其中 $k$ 为标签类型数目(# of distinct tags)。
则有对输出标签序列
\[\mathbf{y} = (y_1, y_2, \dots, y_n) \ ,\]可定义该预测的得分由如下公式得出(CRF)
\[\begin{align} &s(\mathbf{X}, \mathbf{y}) = \overbrace{\sum_{i=0}^{n} A_{y_i, y_{i+1}}}^\text{上下文联系得分} + \overbrace{\sum_{i=1}^{n} P_{i, y_i}}^\text{词对实体预测得分} \\ \text{其中,}&A_{i,j} \text{表示从 tag }i\text{ 到 tag }j\text{ 的一个“语境得分”} \\ &\hspace{1em}(\mathbf{A} \in \mathbb{R}^{(k+2) \times (k+2)}\text{,算上起始标签与结束标签}) \\ \end{align}\]非 CRF 模型直接用输出序列 $\mathbf{y}$ 对 ground-truth 取 SoftMax 即可。
训练目标即为最大化 \(s\) 最高的预测方式的概率。
\[\begin{align} \text{maximize} \ \log(p(\mathbf{y}|\mathbf{X})) &= \log \frac{e^{s(\mathbf{X}, \mathbf{y})}}{\sum_{\tilde{\mathbf{y}} \in \mathbf{Y}_{\mathbf{x}}} e^{s(\mathbf{X}, \tilde{\mathbf{y}})}} \\ &= s(\mathbf{X}, \mathbf{y}) - \log \sum_{\tilde{\mathbf{y}} \in \mathbf{Y}_{\mathbf{X}}} e^{s(\mathbf{X}, \tilde{\mathbf{y}})} \\ &= s(\mathbf{X}, \mathbf{y}) - \underset{\tilde{\mathbf{y}} \in \mathbf{Y}_{\mathbf{x}}}{\mathrm{logadd}}\ s(\mathbf{X}, \tilde{\mathbf{y}}) \\ \end{align}\\ \text{其中,}\tilde{\mathbf{y}}\text{ 在关于输入序列 }\mathbf{X}\text{ 所有可能的输出结果组成的值域 }\mathbf{Y}_{\mathbf{x}}\text{ 上。}\]实现见 src。源码中左右界符在 tag 集中下标分别为 #1, #0。
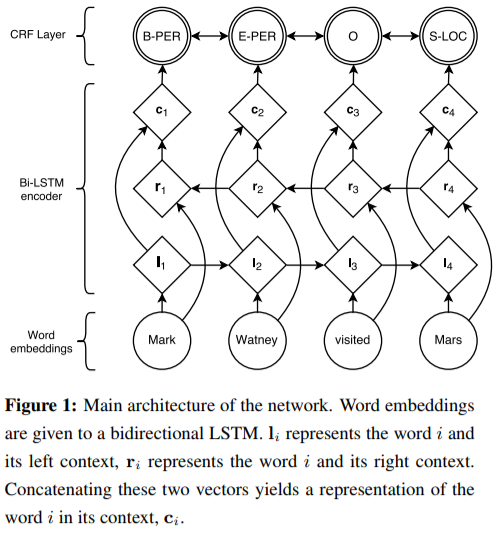 |
|---|
| LSTM-CRF 模型示意图 |
Transition-Based Chunking Model
- Stack-LSTM (Dyer et al., 2015)
- 数据结构
- 输入缓冲区
- 处理栈
- 输出缓冲区
- 操作
SHIFT:输入区中取一个入栈REDUCE(y):栈中符号规约为标志y,入输出区OUT:从输入区中取一个符号直接入输出区
- 数据结构
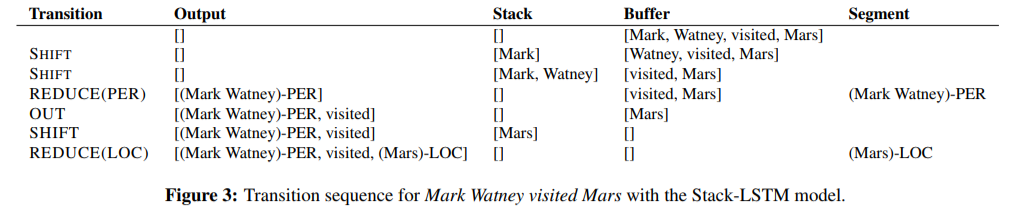 |
|---|
| S-LSTM 操作过程示例 |
简单来说就是编译原理 + 强化学习。
- 扩展词向量
- 考虑到语言中,意思相近 / 有延申含义的词通常有相近的词根,故考虑使用字序列信息(Bi-LSTM 输出)扩展原词向量。
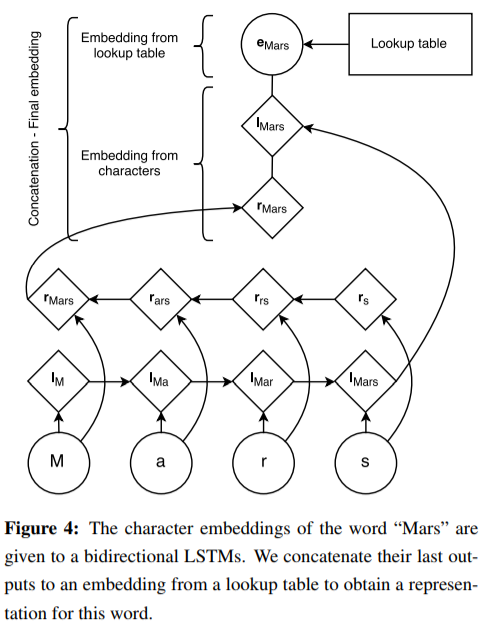 |
|---|
| 字序列信息扩展词向量 |
CharNER: Character-Level Named Entity Recognition
优点:
- 词缀、大小写、标点符号不敏感
- 语言不敏感
- 错误拼写不敏感
-
嵌入向量位于形态学上更抽象维度
… Furthermore, useful sub-word features may vary from language to language, which our model can automatically learn but word-based models would have to incorporate using language-specific resources and features…
- 听说还能让嵌入向量维度更少??
 |
|---|
| CharNet 网络结构示意图 |
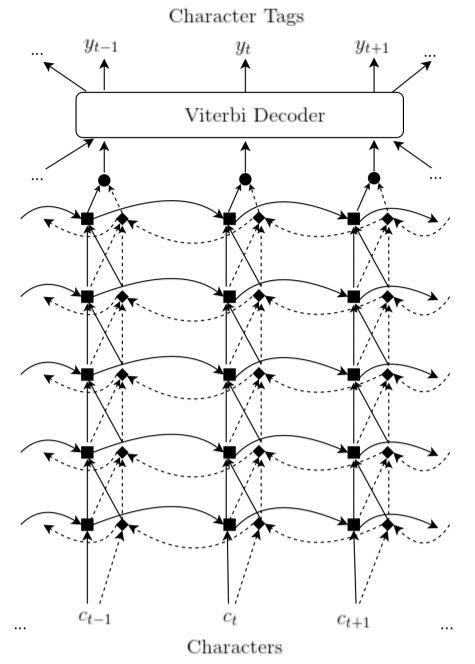
Viterbi Decoder (CRF)
Wiki:
对同一个词,其对每个字的预测标签可能在空间上不连续(如下,对词 abc 预测标签为 PPG)。
char | <spc> a b c <spc> d e ...
label | O P P G O ...
这不利于从字中提出实体对应的词。
该条对非字模型同样适用,因为需要保证标签序列在语义上的连续性与合理性(coherence)。
因此需要构建一个转移矩阵 $\mathbf{A}$,依次为根据对标签预测的连续性进行打分(stochastic)。
类比强化学习中的值函数(状态函数、动作函数、Q 函数)。
令
\[\begin{align} [c]_1^n &= \langle c_1, c_2, \dots, c_n \rangle &\cdots\cdots\text{输入字符序列} \\ [y]_1^n &= \langle y_1, y_2, \dots, y_n \rangle &\cdots\cdots\text{预测标签序列} \\ o(c_i)_{y_i} &= p(y_i \vert [c]_i^i, [c]_i^n) \\ s([c]_1^n, [y]_1^n) &= \sum_{i=1}^n A_{y_{i-1}, y_i} o(c_i)_{y_i} &\cdots\cdots\text{转移得分} \end{align}\]经过 Viterbi 算法打分后,最终输出的预测标签为
\[[y^*]_1^n = \arg \max_{[y]_1^n} s([c]_1^n, [y]_1^n) \ .\]Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
友情链接
RNN 太慢了,不如捞一捞 CNN 吧!
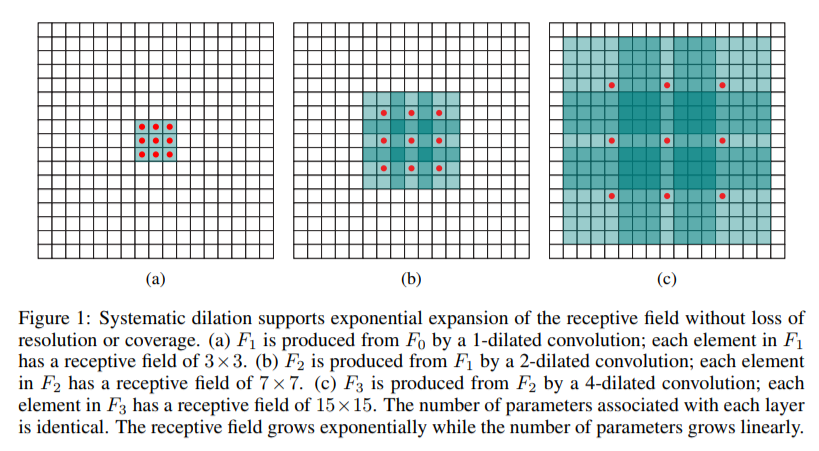 |
|---|
| 膨胀卷积(Dilated Conv.)示意图 |